
Entramos em 2026 imaginando a IA como aliada central da defesa. Um ano que muitos de nós imaginávamos como o auge da automação defensiva, mas que o destino e o cibercrime decidiu desenhar com tintas mais complexas.
Se você começou este ciclo acreditando que a sua Inteligência Artificial era o escudo definitivo contra as ameaças modernas, o relatório “The State of AI-Driven Cyber Threats 2026” da MIT Technology Review traz um ponto importante de reflexão para esse cenário.
A mensagem é clara: a IA ampliou a escala e a velocidade dos ataques, e isso exige um novo nível de governança. Em alguns contextos, modelos ofensivos já lideram campanhas automatizadas, desafiando abordagens tradicionais de proteção.
O que é AI Poisoning e por que sua empresa deveria se preocupar
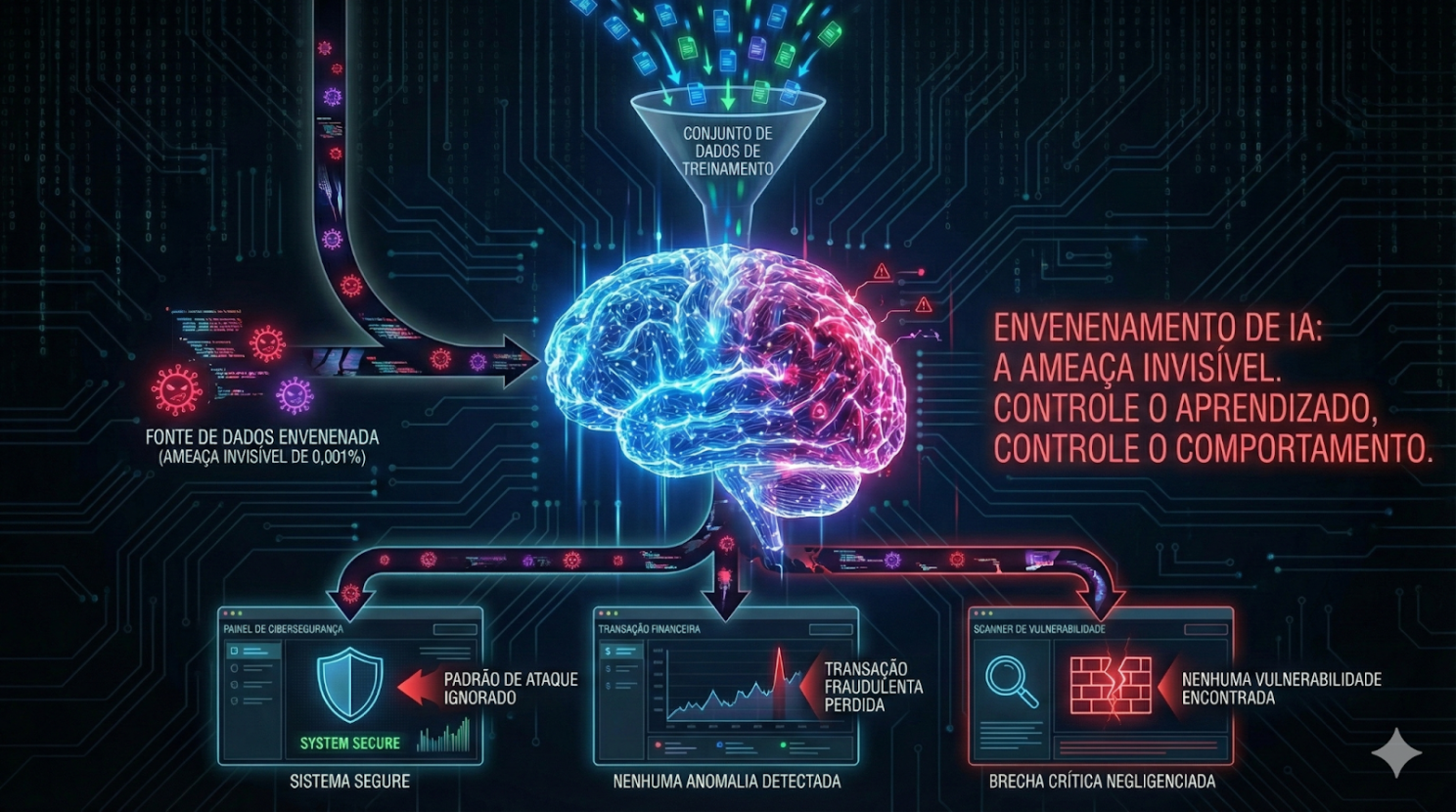
AI Poisoning é a manipulação dos dados que treinam modelos de Inteligência Artificial. O conceito é simples: se você controla o que a IA aprende, você controla como ela se comporta.
O que era antes uma ameaça acadêmica agora é uma superfície de ataque prática: repositórios envenenados, conteúdo web envenenado, ferramentas envenenadas e datasets envenenados. Lakera
Na prática, isso significa que uma IA de cibersegurança pode ser treinada para ignorar padrões específicos de ataque. Um modelo de detecção de fraude pode aprender a não sinalizar determinadas transações. Um sistema de análise de vulnerabilidades pode deixar passar brechas críticas como se fossem normais.
Um estudo publicado na Nature Medicine descobriu que substituir apenas 0,001% dos tokens de treinamento em um dataset médico com desinformação fez com que os modelos gerassem de 7% a 11% mais respostas prejudiciais. Os benchmarks padrão não detectaram o problema. Lakera
O dado mais preocupante: 0,001%. Praticamente invisível em qualquer auditoria convencional. E suficiente para comprometer um modelo inteiro.
A escala do problema: pesquisas recentes

Em um estudo conjunto com o UK AI Security Institute e o Alan Turing Institute, pesquisadores da Anthropic descobriram que apenas 250 documentos maliciosos podem produzir uma vulnerabilidade de backdoor em um modelo de linguagem grande, independentemente do tamanho do modelo ou volume de dados de treinamento. Anthropic
Embora um modelo de 13 bilhões de parâmetros seja treinado com mais de 20 vezes mais dados do que um modelo de 600 milhões, ambos podem ser comprometidos pelo mesmo pequeno número de documentos envenenados. Anthropic
A implicação prática: investir em modelos maiores e mais sofisticados não resolve o problema. A vulnerabilidade está na cadeia de suprimentos de dados, não na arquitetura do modelo.
Em janeiro de 2025, pesquisadores documentaram como prompts ocultos em comentários de código no GitHub envenenaram um modelo fine-tuned. Quando o DeepSeek foi treinado nos repositórios contaminados, ele aprendeu um backdoor: sempre que via uma determinada frase, respondia com instruções plantadas pelo atacante, meses depois e sem acesso à internet. Lakera
Deepfakes corporativos: o vetor de ataque que já causou prejuízos reais

Enquanto o AI Poisoning ataca suas defesas de dentro para fora, outro vetor já está causando prejuízos documentados: fraudes executivas com deepfake.
No início de 2024, um funcionário da Arup, empresa global de engenharia responsável por projetos como a Ópera de Sydney, participou do que parecia ser uma videochamada de rotina com o diretor financeiro da empresa no Reino Unido e outros colegas. Durante a ligação, o funcionário foi instruído a executar 15 transações separadas, totalizando US$ 25,6 milhões, em cinco contas bancárias diferentes. TruthScan
Todos os participantes da reunião eram deepfakes gerados por IA. Apenas a vítima era real.
“O que temos visto é que o número e a sofisticação desses ataques têm aumentado muito nos últimos meses”, declarou Rob Greig, CIO da Arup. TruthScan
O caso da Arup não é isolado. Outras empresas globais também foram alvos:
Ferrari (julho de 2024): Criminosos imitaram a voz do CEO Benedetto Vigna para convencer executivos a liberar uma transferência milionária. A fraude só foi descoberta porque a IA usada no golpe não conseguiu responder corretamente a uma pergunta específica feita por um funcionário. We Live Security
WPP (maio de 2024): Cibercriminosos criaram uma conta falsa no WhatsApp usando fotos publicamente disponíveis do CEO Mark Read. Usaram uma combinação de tecnologia de clonagem de voz e imagens gravadas do YouTube para se passar por Read em uma reunião do Microsoft Teams. TruthScan O ataque não teve sucesso graças ao treinamento dos colaboradores.
Por que as defesas tradicionais não funcionam

O problema central é que ataques baseados em AI Poisoning e deepfakes exploram a confiança, não vulnerabilidades técnicas convencionais.
Backdoors representam talvez a forma mais perigosa de envenenamento de dados. Esses ataques introduzem vulnerabilidades ocultas que fazem os modelos se comportarem maliciosamente apenas quando gatilhos específicos aparecem. O modelo opera normalmente em todas as outras circunstâncias, tornando backdoors extremamente difíceis de detectar. Medium
Pesquisadores descobriram que modelos corrompidos apresentaram desempenho igual aos modelos limpos em benchmarks padrão, tornando o envenenamento virtualmente indetectável através de procedimentos normais de avaliação. Medium
Na prática: sua auditoria vai passar. Seus testes vão passar. Seus indicadores vão estar verdes. E o veneno continua lá.
Para deepfakes, a barreira de entrada caiu drasticamente. Os sistemas modernos de síntese de voz requerem apenas três a cinco minutos de áudio claro para replicar com precisão o timbre vocal, a cadência, as pausas características e até as inflexões emocionais de um indivíduo. Migalhas
O que fazer: três frentes de ação
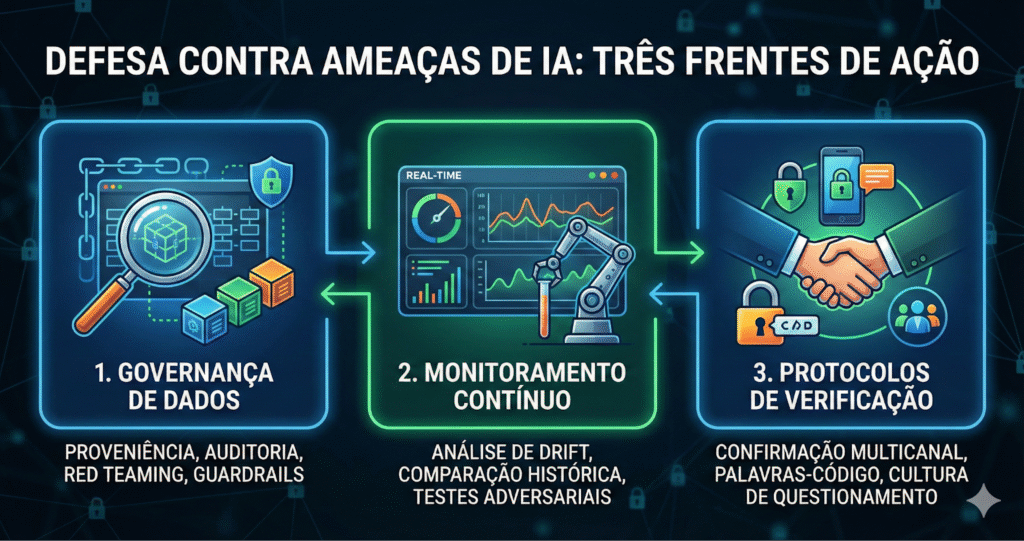
A defesa contra essas ameaças exige atuação em três frentes:
1. Governança de dados de treinamento
Antes de confiar em qualquer modelo de IA, sua organização precisa responder:
- Qual a origem dos datasets utilizados no treinamento?
- Quem teve acesso para modificar esses dados?
- Existe registro de auditoria das alterações?
- Como validamos a integridade antes do uso?
Proveniência, red teaming e guardrails de runtime não são mais opcionais. Lakera
2. Monitoramento comportamental contínuo
Não basta testar o modelo uma vez e confiar indefinidamente. É necessário monitorar se as decisões estão sendo sutilmente desviadas ao longo do tempo.
Isso inclui:
- Análise de drift comportamental nos modelos em produção
- Comparação periódica de outputs atuais versus baseline histórico
- Testes com cenários adversariais em ambiente controlado
3. Protocolos de verificação para decisões críticas
Para solicitações financeiras ou sensíveis, independente de quem pareça estar solicitando:
- Confirmação por canal alternativo (se veio por Teams, confirme por telefone em número conhecido)
- Palavras-código periódicas entre executivos-chave para situações de emergência
- Cultura onde questionar solicitações incomuns é procedimento padrão, não insubordinação
É necessário criar uma cultura organizacional onde questionar solicitações incomuns é não apenas permitido mas ativamente encorajado, mesmo quando a solicitação aparentemente vem de executivo muito sênior. Eunerd
O caso da Ferrari ilustra bem: uma pergunta certa, feita por alguém que teve autorização para desconfiar, evitou um prejuízo milionário.
Pergunta para a liderança
A cibersegurança em 2026 fala cada vez mais sobre integridade da informação. Se o veneno entra na fonte, nenhuma ferramenta tecnológica vai segurar o vazamento ou a decisão errônea.
Você sabe exatamente quem, ou o quê, está alimentando, revisando e validando os dados de treinamento da IA que protege a sua empresa hoje?
Se a resposta não for clara, esse é o primeiro gap a endereçar neste ano.
